어제는 Computer vision의 인식 단계 중 texture에 대해서 알아보았습니다.
오늘은 한 단계 더 나아가, 상위 개념인 Shape에 대해서 알아보겠습니다.
밑의 이미지는 어제 대충 휘갈긴 인식 피라미드 그림인데, 생각보다 걸작인지라 재탕하겠습니다.
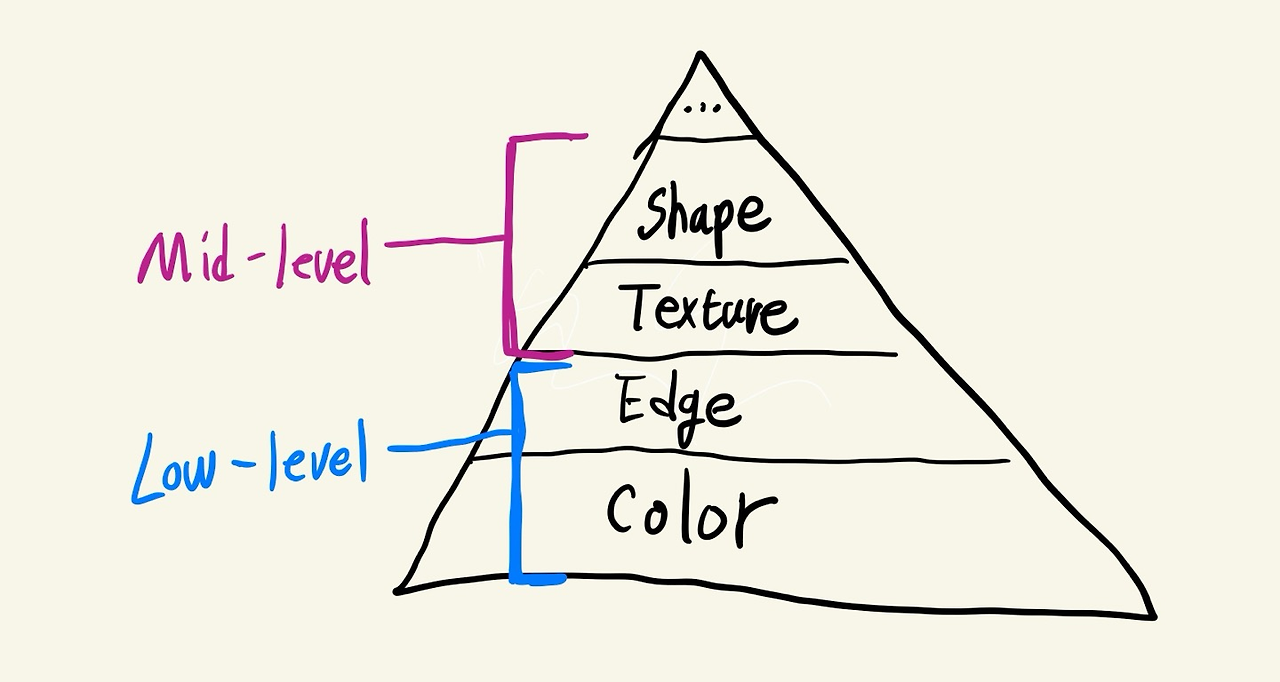
컴퓨터비전에서 Shape는 객체의 형태 또는 구조를 의미하며, image 상에서 물체를 인식하고 구분하는 데 쓰입니다.
예시를 들자면, 위의 인식 피라미드 Image에서 삼각형 모양이 Shape가 될 수 있겠습니다.
앞서 설명드린 Color 혹은 Texture와 같은 경우, Image 안에서 global하게 존재하는 특징입니다.
그러나 Shape는 이미지 안에서 local한 특징입니다. 이러한 차이점을 먼저 짚고, shape를 만들 수 있는 3가지 접근법 알아봅시다.
1. By it's region descriptor
2. By it's boundary
3. By it's interest points
이제 각 방법에 대해 자세히 알아보겠습니다.
[1] Region based Shape Descriptors
Image 내 Shape를 나타내는 방법 중 하나로, 객체의 경계가 아닌 객체의 내부 영역을 분석하여 shape를 설명합니다.
객체의 내부 영역을 본다는 건 내부 영역의 면적 및 모멘텀, 무게중심, 경계선의 길이 등을 본다 생각하시면 이해가 쉬울 것 같습니다.
이를 위해 쓰이는 다양한 parameter들이 있는데, 그 중 대표적인 (혹은 제 기말고사에 나올 법한) 몇 가지에 대해 알아보겠습니다.
(1) 면적, Area
: 객체의 픽셀 수 혹은 실제 면적을 말합니다. 객체 크기 비교 및 필터링에 사용됩니다.
(2) 중심, Centroid
: 객체의 무게 중심입니다. 객체를 구성하는 모든 점의 좌표 평균이고, 객체의 위치 추적 및 비교에 쓰입니다.
(3) 둘레 길이, perimeter length
: 객체의 둘레에 위치한 점의 길이, 둘레의 길이입니다.
(4) 모멘트, Moment
: 객체의 기하학적 특성을 설명하는 값들로, 중심 모멘트 / 정규화 중심 모멘트 / Hu 모멘트가 있습니다.
(5) 비율, Aspect Ratio
: 객체를 bounding 할 때의 width / height 값으로, 객체의 세로형 or 가로형 여부를 판단합니다.
(6) 원형도, Compactness
: 객체의 면적과 둘레 길이의 비율, 정사각형을 원과 유사하다고 판단할 수 있음에 주의합니다.
(7) 이심률, Eccentricity
: 객체의 원형 또는 타원형을 판단해줍니다. 장축과 단축의 비율.
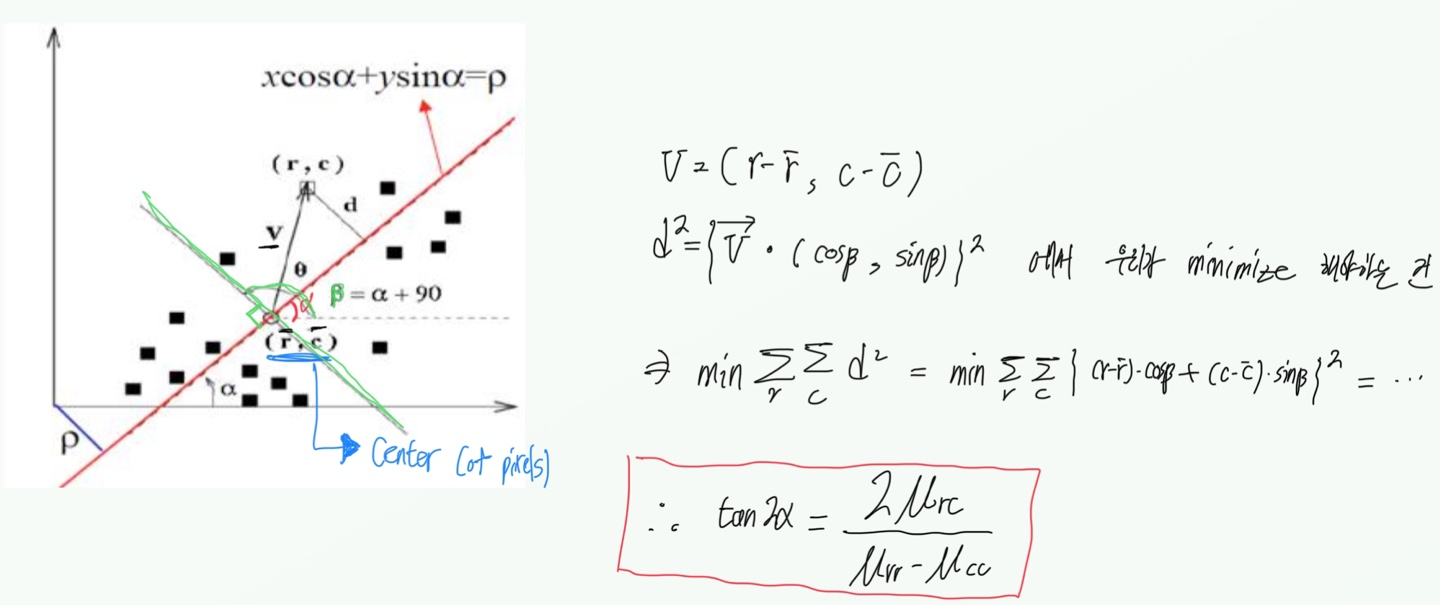
(8) 방향성, Orientation
: 객체 내부 영역의 방향성, 각 점과 이루는 거리의 합을 minimize하는 직선의 기울기입니다.
이 외에도 Convexity, Solidity 등등이 있습니다.
밑에서는 두 이미지를 입력받아 해당 이미지를 Hu 모멘트를 계산하여 윤곽선을 찾고, 모양을 비교한 후 거리 값을 출력하는 간단한 예제 코드를 보여드리겠습니다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
def calculate_hu_moments(image_path):
# 이미지 불러오기 및 그레이스케일로 변환
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 이진화
_, binary = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
# 윤곽선 찾기
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 첫 번째 윤곽선 사용
if len(contours) == 0:
raise ValueError(f"No contours found in image: {image_path}")
cnt = contours[0]
# 모멘트 계산
moments = cv2.moments(cnt)
# Hu 모멘트 계산
hu_moments = cv2.HuMoments(moments).flatten()
# 로그 스케일로 변환 (숫자의 크기를 줄이기 위해)
log_hu_moments = -np.sign(hu_moments) * np.log10(np.abs(hu_moments))
return log_hu_moments, contours, binary
def plot_contours(image_path, contours, ax):
# 원본 이미지 불러오기
image = cv2.imread(image_path)
# 윤곽선 그리기
cv2.drawContours(image, contours, -1, (0, 255, 0), 2)
# 이미지를 RGB 형식으로 변환 (OpenCV는 BGR을 사용하므로)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 이미지 출력
ax.imshow(image_rgb)
ax.axis('off')
def compare_shapes(image_path1, image_path2):
hu_moments1, contours1, binary1 = calculate_hu_moments(image_path1)
hu_moments2, contours2, binary2 = calculate_hu_moments(image_path2)
# L2 거리로 모양 비교
distance = np.linalg.norm(hu_moments1 - hu_moments2)
return distance, contours1, contours2, binary1, binary2
# 이미지 경로
image_path1 = 'Write your image1 path'
image_path2 = 'Write your image2 path'
# 모양 비교
distance, contours1, contours2, binary1, binary2 = compare_shapes(image_path1, image_path2)
print(f"Shape similarity (lower is more similar): {distance}")
# 시각화
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
plot_contours(image_path1, contours1, axes[0])
axes[0].set_title('Image 1 with Contours')
plot_contours(image_path2, contours2, axes[1])
axes[1].set_title('Image 2 with Contours')
plt.show()
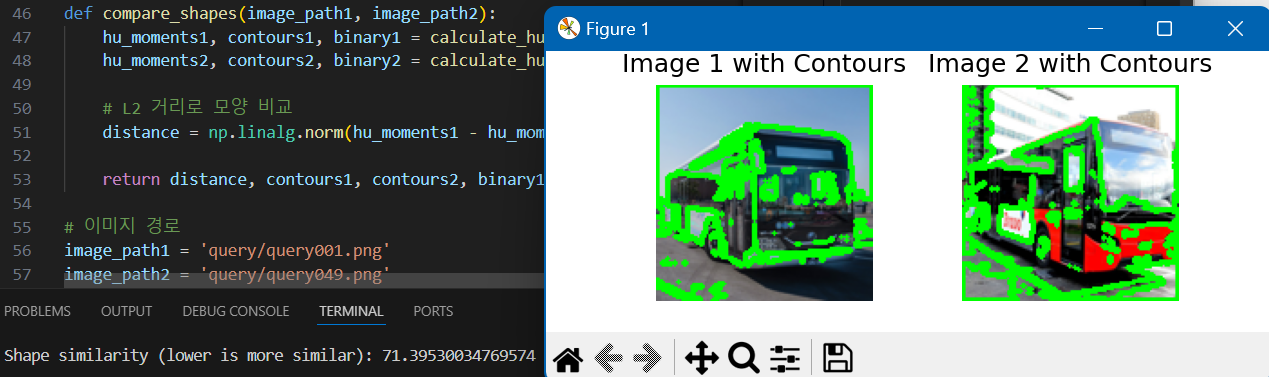
아래 사진은 제가 비교한 두 120x120 버스 이미지의 비교 결과입니다.
[2] Boundary based Shape Descriptors
다음으로는 객체의 경계선을 중심으로 shape를 설명하는 방법입니다.
사실 이 파트는 제 강의 자료에는 거의 스킵(?)하는 부분이지만 Freeman Chain Code라는 유일한 내용이 있어 작성합니다.
Freeman Chain Code는 객체의 경계선을 디지털화된 형태로 표현하는 방법으로, 4방향 or 8방향으로 추적하여 객체의 경계선을 chain code로 변환합니다.

8방향 Freeman chain code 예시입니다. 만약 4방향을 채택한다면, 0 -> 7 -> 6 순서가 아니라 0 -> 0 -> 3 -> 3 의 경로를 따르게 되고, 그에 따른 메모리가 추가로 소모될 수 있겠습니다. 하지만 8방향은 chain code의 dimension이 2배로 증가한다는 단점이 있습니다. 세상에 공짜는 없다는 걸 상기시켜줍니다. 대머리 되는 게 쉬운 일은 아니네요.
이 외에도 푸리에 변환을 이용한 방법 등이 있지만, 시험범위 외의 공부는 현재로선 사치이기에 추후에 공부해보겠습니다.
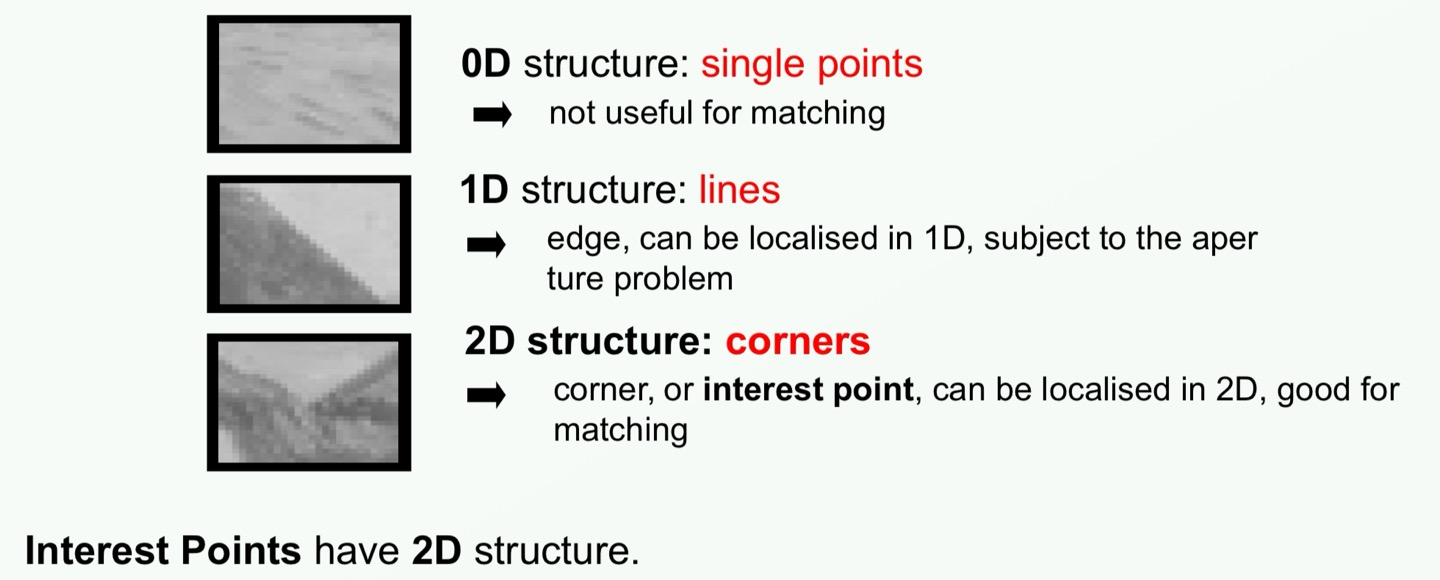
[3] Interest operator based Shape Descriptors
이미지에서 중요하다고 판단되는 특징 점인 interest point나 corner를 검출하고, 이러한 점들의 주변의 특징을 기반으로 객체의 모양을 기술하는 방법입니다. 저 같이 뇌의 강도가 굳센 사람은 굳이 모든 걸 이해하려 하면 시간 대비 공부 능률이 떨어지기에 몇 가지 대표적인 알고리즘 3가지에 대해서만 공부하겠습니다.
(1) Harris corner detector
Image에서 corner를 검출하는 알고리즘입니다. 각 픽셀의 gradient를 계산하고, 코너의 강도인 response를 평가하여 코너를 검출합니다. 혹여 gradient 계산은 1편의 edge 파트를 참고해주시면 감사하겠습니다.
간단하고 빠른 알고리즘이지만, Image의 scale에 따른 불변성을 보장해주지는 못합니다. Watermelon sugar 라는 노래가 듣고싶어지는 알고리즘이기도 합니다.
(2) SIFT - Scale Invariant Feature Transform
Image의 scale과 rotation에 불변하는 특징을 검출하는 알고리즘입니다. Scale 공간에서 Gaussian filter를 사용하여 image smoothing을 해준 뒤, 다양한 스케일에서 이미지의 키포인트를 검출합니다. 이후 local maximum 값을 검출해 키포인트 후보를 선정하고, 각 키포인트에 방향을 할당합니다. 1차적으로 gradient thresold 를 해주고 이후 ratio thresold 까지 해주는 알고리즘입니다.

위의 이미지에서 순서를 참고해서 봐주시면 되겠고, 2,3,4번에서 옆에 써져 있는 숫자는 keypoint의 개수입니다.
코드로 살펴보겠습니다.
import cv2
import matplotlib.pyplot as plt
# 이미지 불러오기
image_path = 'path_to_image.jpg'
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# SIFT 특징점 검출기 생성
sift = cv2.SIFT_create()
# 특징점 검출
keypoints = sift.detect(gray, None)
# 이미지에 특징점 그리기
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 결과 시각화
plt.figure(figsize=(12, 8))
plt.imshow(cv2.cvtColor(image_with_keypoints, cv2.COLOR_BGR2RGB))
plt.title('Image with SIFT Keypoints')
plt.axis('off')
plt.show()
밑은 버스 이미지에 SIFT를 적용하여 keypoint를 검출한 결과입니다.

버스가 귀여워졌습니다.
(3) HOG - Histogram of Oriented Gradient
1편에서 edge를 검출할 때 쓰는 filter(mask)에 대해 공부하면서, Sobel filter에 대해서도 알아보았습니다.
HOG는 이 Sobel 필터를 사용하여 Image의 각 픽셀에서 gradient의 크기(magnitude)와 방향(direction)을 계산합니다.
이를 바탕으로 gradient histogram을 생성하고, block 단위로 나뉘어진 Image의 gradient histogram을 정규화합니다.
만들어지는 histogram은 정규화 작업을 통해 밝기 변화에 invariant하게 되고, bin값은 (x축 구간 개수) 주로 9개를 사용하여 9차원 vector가 됩니다. Block gradient histogram을 모두 연결하여 최종적으로 이미지의 HOG 벡터를 생성하게 되고, 이는 SVM 등의 머신러닝 학습에 입력 벡터로 사용되게 됩니다.
위의 SIFT 알고리즘과 마찬가지로 Scale / Rotation 등에 불변하는 성질을 가지며, 객체의 테두리 정보를 잘 감지하기에 많이 사용되는 알고리즘입니다. 밑에서 코드 예제 및 실행 결과 살펴보겠습니다.
import cv2
import matplotlib.pyplot as plt
from skimage.feature import hog
from skimage import exposure
# 이미지 불러오기
image_path = 'Write your image path'
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# HOG 특징 추출
fd, hog_image = hog(gray, orientations=9, pixels_per_cell=(8, 8),
cells_per_block=(2, 2), visualize=True)
# 이미지 밝기 조절
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
# 결과 시각화
plt.figure(figsize=(12, 8))
plt.subplot(1, 2, 1)
plt.imshow(gray, cmap='gray')
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(hog_image_rescaled, cmap='gray')
plt.title('HOG Features')
plt.axis('off')
plt.tight_layout()
plt.show()
아래는 버스 이미지를 입력으로 주었을 때, HOG 실행 결과입니다.

버스가 무서워졌습니다.
'컴퓨터비전 (CV)' 카테고리의 다른 글
| [컴퓨터비전] (5) Linear Regression, 선형회귀분석 (5) | 2024.07.24 |
|---|---|
| [컴퓨터비전] (4) Image Segmentation, 이미지 분할 (0) | 2024.07.12 |
| [컴퓨터비전] (2) Texture 에 대하여 (2) | 2024.06.13 |
| [컴퓨터비전] (1) Color, Edge에 대하여 (0) | 2024.03.31 |



