지난 학기에 컴퓨터비전 수업을 수강하며, 한 학기에 걸쳐 이미지 매칭 시스템을 만드는 챌린지를 했었습니다.
주어진 사물 이미지 데이터를 학습하여 새로운 이미지를 분류하는 프로젝트였고, 개인 프로젝트로 진행이 되었습니다.
사물 이미지는 총 10개의 class로 이루어져 있으며, 이를 도메인으로 삼아 진행됐던 챌린지였습니다. 주어진 이미지 데이터셋 학습을 미리 마친 상태로 챌린지 당일 노트북을 들고가서 주어지는 100개의 새로운 이미지를 분류하면 됐습니다. 그리고 하나의 챌린지였지만 늘 그렇듯 4개의 꼬리 문제로 구성이 되어있었는데, 각 문제는 다음과 같습니다.
1. low-level한 특징 추출만을 결합하여 새로운 이미지를 하나의 class로 classification 하는 문제 (c1_t1)
2. low-level한 특징 추출만을 결합하여 새로운 이미지를 유사도 상위 10개의 class로 retrieval 하는 문제 (c1_t2)
3. high-level한 CNN을 활용하여 새로운 이미지를 하나의 class로 classification 하는 문제 (c2_t1)
4. high-level한 CNN을 활용하여 새로운 이미지를 상위 유사도 10개의 class로 retrieval 하는 문제 (c2_t2)
각 항목에 대해 간단한 리뷰를 작성해보고자 하는데, 코드 전체를 올리면 추후에 같은 수업을 듣는 학우분의 발전 가능성을 해칠 수 있기에 부분부분 리뷰해보도록 하겠습니다. 물론 제 코드 전체를 베껴도 점수가 잘 나온다는 보장은 없지만요. 게다가 약 3달 전 마무리 된 프로젝트기에 기억이 가물가물하여 정확하지 않은 정보가 있을 수 있습니다. 하핫.
먼저 프로젝트 환경 에 대해 간단히 설명드리겠습니다.

이 프로젝트에서 쓰일 이미지의 도메인은 위 사진과 같은 10개의 class로 구성되어있습니다. 각 항목에 해당하는 이미지 데이터를 clone해와 진행하는 방식이었고, 각 클래스 별로 적게는 50장부터 시작하여 많게는 3000장의 이미지 데이터가 있었습니다. 각 클래스 별 이미지 데이터 개수의 차이가 큰 편이었던 것 같습니다.

프로젝트는 VS code의 Python 환경에서 진행되었으며, OpenCV, scikit-image, scikit-learn, tensorflow-keras 등의 라이브러리를 가져와 작업하였습니다. 분류기로는 SVM을 사용하였고, 학습한 SVM 분류기를 joblib 라이브러리를 이용하여 저장하였습니다. 분류/예측한 결과는 .csv 파일로 저장하여 소스 코드와 함께 제출하는 방식이었습니다.
이제 각 꼬리 문제 리뷰 시작하겠습니다.
[1] low-level한 특징 추출만을 결합하여 새로운 이미지를 하나의 class로 classification (c1_t1)

말이 너무 길어 c1_t1으로 부르겠습니다. c1_t1 에서의 아이디어에 대해 설명드리겠습니다.
주어진 이미지들의 평균 color값의 분포를 맞춰주기 위해 먼저 color 정규화를 하는 전처리 과정을 거친 뒤, 전처리된 이미지들을 Law's texture + GLCM의 조합으로 특징을 추출했습니다.
이미지 데이터 상에서 law's texture를 활용하여 좁은 공간에서의 국부적인 텍스처를 분석하며, GLCM을 통해 픽셀 간의 공간적 배치 분석 등을 통해 전역적인 텍스처 분석을 할 수 있어 상호보완적인 방식으로 이미지 특징을 추출할 수 있다는 아이디어였습니다.
이후 각 클래스 별 이미지들을 학습시킨 뒤, SVM 분류기에 저장하여 챌린지 당일날 받은 이미지 파일을 classfication 했습니다.

그렇게 대회 당일 위과 같은 결과가 나오게 됩니다. 새로운 이미지인 query006.png 를 제 프로그램은 오토바이로 인식한 모습입니다.
[2] low-level한 특징 추출만을 결합하여 새로운 이미지를 유사도 상위 10개의 class로 retrieval (c1_t2)
여기서도 c1_t1과 동일하게 컬러 정규화 및 law's texture + GLCM의 조합으로 특징을 추출했습니다. c1_t2를 진행하며 c1_t1과의 차이점은, 단순하게 1개의 class로 classification 하는 것이냐 / 확률 순으로 10개 class로 retrieval 하는 것이냐 이었습니다. 그렇기에 해당 부분의 코드만 바꾸어 진행했습니다.

c1_t1과 c1_t2를 종합하여 평을 내려보자면, 잘 한 것 같지는 않습니다.
각 클래스에 해당하는 트레이닝 이미지 개수 차이가 매우 컸기에 이를 고려하여 데이터셋의 개수를 조절하여 과적합/과소적합을 방지했어야 하는데, 그걸 간과했던 점과 특징 결합에 사용한 로직이 너무 단순했던 것 같습니다. shape의 특징을 조금 더 고려했으면 좋았을 것 같습니다.
[3] high-level한 CNN을 활용하여 새로운 이미지를 하나의 class로 classification (c2_t1)
c2_t1 입니다. 트레이닝 이미지가 담겨있는 폴더의 경로로부터 이미지들을 불러와 CNN을 사용하여 주어진 데이터셋을 학습시켰습니다. 전처리한 데이터의 20%는 검증용으로, 80%는 학습용으로 사용하였고 CNN의 Sequential API를 사용하여 층을 쌓아가는 방식으로 신경망을 구성했습니다.
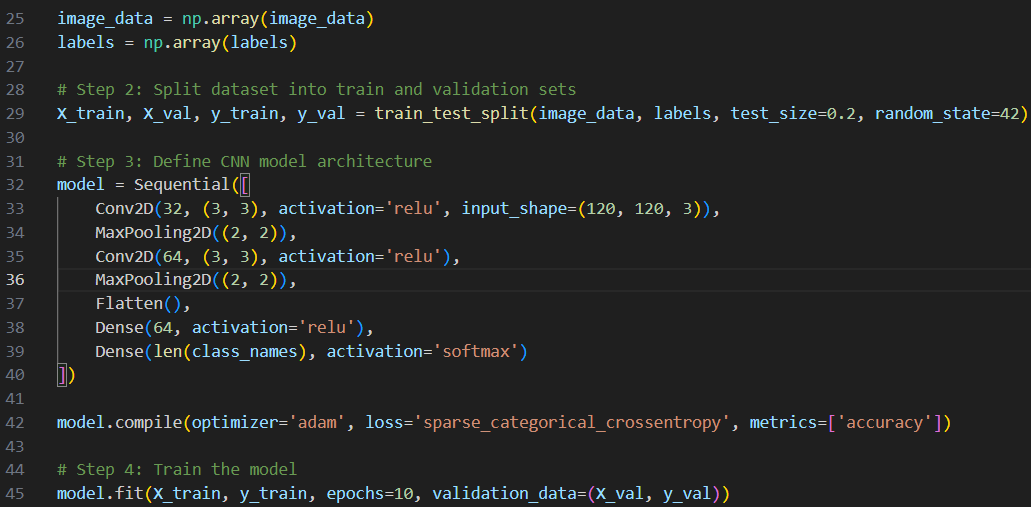
이렇게 CNN을 통해 학습시킨 프로그램을 통해 모델을 분류하게 되면, 다음과 같은 결과가 나오게 됩니다. CNN 구성 정보도 확인하실 수 있습니다.
이론상으로는 앞선 low-level한 특징을 이용하는 것보다 훨씬 어려워 보이지만, 실제로 구현하는 과정 자체는 이미 존재하는 라이브러리와 함수를 짜집기만 하면 되기에(...) c1보다 c2가 더 편했던 것 같습니다. 근데 예측 결과도 (당연히) 더 좋으니 만약 다시 돌아간다면 c1의 성능을 높이는 방향으로 프로젝트를 진행할 것 같습니다.
[4] high-level한 CNN을 활용하여 새로운 이미지를 상위 유사도 10개의 class로 retrieval (c2_t2)
c2_t1과 동일하게 CNN을 활용하여 주어진 이미지를 처리하는데, 이 때 c2_t2에서는 이미지가 속할 확률이 높은 순으로 10개의 클래스를 나열해야 했습니다. 앞선 로직까지는 마찬가지로 같고, 이미지가 각 클래스에 속할 확률을 결정하는 결정함수 코드를 구현하면 되었습니다. 저는 model.predict(images) 에서 softmax 활성화 함수를 통해 각 클래스에 속할 확률을 반환하게 했습니다.

이후 작성한 c2_t2 코드를 돌려보면, 다음과 같은 c2_t2.csv 파일이 생성되게 됩니다.
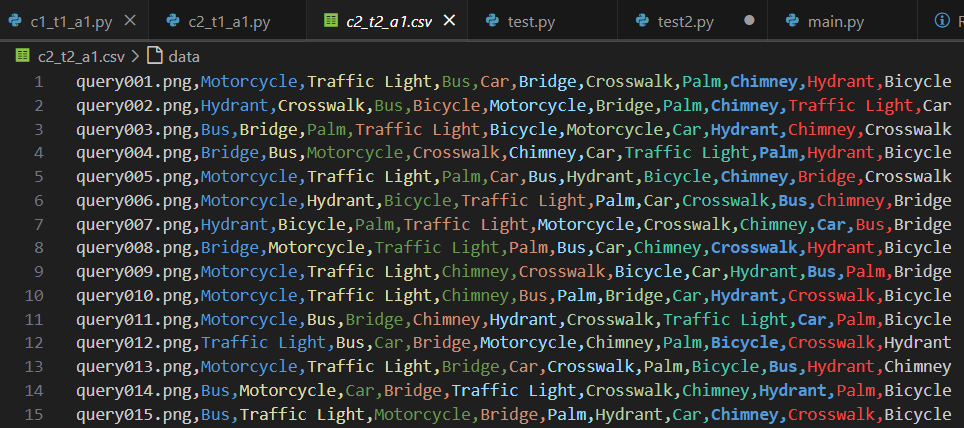
c1_t2파일과 비교했을 때, 결과 데이터 분포가 더욱 고르고 정확도도 높은 것 같습니다.
당연합니다. CNN은 제가 쓴 코드보다 똑똑할 것이니까요. 참고로 예측 결과의 정확도는 밝히지 않았습니다.
이렇게 Image Matching System 챌린지에 대한 간단한 리뷰를 마치겠습니다.
개인 프로젝트였고, 친한 과 동기 한 명 없었기에 ChatGPT와 열심히 협업(?)해가며 완성했던 프로젝트였습니다.
올해 들어 갑자기 관심이 생긴 컴퓨터비전 분야였기에, 분명 어려웠지만 재밌기에 포기하고 싶었어도 계속 진행했었습니다. 적정하게 피팅할 수 있는 이미지 개수, 이미지 전처리를 어떻게 해야할지, low-level한 특징을 어떻게 조합하여 사용해야 다양한 image에 대해 invariant 할 수 있을지 등등... 성능 더 높이기 위한 다양한 고민을 하며 조금이나마 성장할 수 있었던 것 같습니다.
프로젝트의 아이디어나 진행과정이 미숙했고 아쉬움도 들지만, 처음 접하는 분야를 공부와 병행하며 작업하여 결과를 만들어냈다는 뿌듯함이 더 큰 것 같습니다. 긴 글 읽어주셔서 감사드립니다.
'Project' 카테고리의 다른 글
| 졸업프로젝트 회고록 (2) | 2025.03.17 |
|---|---|
| [안드로이드] 클라이밍 자세 피드백 앱 preview (11) | 2024.10.07 |

